
The Secret Control Plane for the Agentic Revolution
Business explained, a structural force named, and a position taken. The 2nd Order and Hidden Market Gems take Snowflake from the ground up in this first collab post.



Please before diving in, read this disclaimer.
A collaboration between Emerald from The 2nd Order and Hidden Market Gems.
Before we get into it, a word on how this one came together.
I run Hidden Market Gems, a newsletter focused on under-the-radar listed equities before the market prices them correctly. If you follow Future Cognitive Capital, you already know Emerald. If this is your first time seeing both names in the same place: FCC is where we converge on a structured framework, eight cognitive dimensions and five financial criteria, applied to the names that sit at the intersection of structural forces and listed equities. I run the bottom-up equity side. Emerald runs the macro with Crystal.
We have been looking at Snowflake for several months, and then Emerald did something I find genuinely rare: published a clean, time-stamped thesis before earnings, named the mechanism, and turned out to be comprehensively right. That call is here:

The stock moved 37% overnight on May 27. A conviction call that precise, validated that fast, deserves more than a screenshot. It deserves a proper post-mortem and a forward case, built together! So we built one.
What follows is a full business deep dive on Snowflake: the actual architecture first, then the structural case Emerald has been describing in the post, then the investment question as it stands now that the first leg of the re-rating is done. Two desks, but only one piece.
I highly recommend you to check Emerald newsletter. It’s about macro, politics, systems (I don’t fully understand) and right calls on tech!
Go check this one piece:
Or this one!
This research is allowed by the contributor of Hidden Market Gems and The 2nd Order. They directly fund the research, the late night Discord calls, the paid licences of data or AI, the coffee and tea…
In exchange, they have good research to invest in a fast changing world.
Sounds good? Consider becoming a paid subscriber.
let’s go to the article:

Snowflake
You would be forgiven for missing Snowflake in 2026.
The company was doing record revenue, signing the largest infrastructure deal in its history, and shipping twenty-six new products at its annual conference. But the stock had lost half its value from peak while every other AI-adjacent name was ripping, and at some point the eye stops following the asset that keeps going wrong.
Then May 27 happened, and the stock added 37% overnight. A $5 billion revenue business rarely moves that way on a routine beat. Something structural had been systematically mispriced, and the market noticed all at once.
You are not forgiven for missing it from now.
Understanding what actually happened requires three things. First, a real understanding of what Snowflake built and how the machine works. Second, the structural case for why the data layer is being repriced across the entire AI economy right now, and why Snowflake sits at its center. Third, the position: where the dislocation was, what the print proved, and whether the move is done.
We decided to not to to it anonymously, there are two desks. I, HMG takes the business and the investment and Emerald takes the strategy, that way we converge at the end.
What Snowflake Actually Built
— Hidden Market Gems
Most of the coverage calls Snowflake a “data company,” which is approximately as useful as calling a semiconductor fab a “manufacturing company.” It tells you the industry and nothing about the business. So let me start in 2012, because the architecture is the product, and the architecture is where the story begins.
The problem before Snowflake
Enterprise data management in the early 2010s was an economics problem disguised as a technology problem. The dominant on-premises systems, Oracle, Teradata, Netezza, were expensive in a very specific way: compute and storage were physically coupled. More data meant a bigger box, and a bigger box meant more compute whether you were using it or not. You paid for peak capacity at all times, even when your actual usage was a fraction of that.

The practical consequence was that companies got conservative with their data. You couldn’t afford to keep everything. You ran scheduled batch jobs overnight to avoid slowing down the daytime workload. You sampled datasets instead of running full analyses.
You built separate systems for separate teams and then spent years trying to reconcile them. The finance team’s revenue number and the sales team’s revenue number disagreed, which is a problem every CFO reading this has already lived through.
Amazon launched Redshift in 2012, and it was a genuine improvement: cloud-based, no hardware to maintain, cheaper to scale. But it still ran on the same architectural assumption. Compute and storage moved together. And it was an Amazon product, which meant it was AWS-only, which mattered increasingly as enterprises were already distributing their workloads across AWS, Google Cloud, and Azure simultaneously.
That same year, three engineers who had spent their careers at Oracle left to build Snowflake. Benoit Dageville, Thierry Cruanes, and Marcin Zukowski knew what was broken from the inside.
The architectural bet of Snowflake
Their insight was to build natively for cloud object storage, specifically AWS S3, as the persistent storage layer. S3 is cheap, durable, effectively unlimited, and already managed by Amazon at scale. The question was whether you could build a high-performance query engine on top of it, given that object storage has very different access characteristics than traditional databases.
With a significant amount of caching and metadata engineering, the answer was yes. And once you separated compute from storage, a set of consequences followed naturally.

The first was elasticity: spin up compute for a query, run it, spin it down. No idle capacity. Pay per second of actual use.
The second was parallelism: Snowflake calls its compute units Virtual Warehouses, and you can run multiple of them simultaneously, each reading the same underlying data without interference.
The finance team running end-of-quarter reports does not slow down the data science team training a model on the same dataset. Each team gets its own lane.
The third was multi-cloud: if the underlying storage is abstracted away from compute, you can run queries against data stored on AWS, on Google Cloud, or on Azure, using the same interface and the same governance policies.
For the enterprise that has workloads distributed across multiple hyperscalers, this means a single platform instead of three competing systems. Snowflake positioned itself as neutral ground, and that turned out to be strategically important in a way nobody fully appreciated until the hyperscalers themselves started building competing products.
The consumption model
The pricing followed the architecture, in fact, customers pay for the compute they actually use, measured in credits, not for a fixed license or a per-seat fee. Light queries mean a light bill. Intensive workloads during a quarterly close or a product launch mean higher spend during that window, then it drops back.
The model aligns the vendor’s revenue with the customer’s actual use.
This creates an unusual dynamic in enterprise software. New workloads can come onto the platform without a procurement cycle. Experimentation has a low cost floor. Customers who expand organically drive revenue expansion without a new contract.
The flip side became the center of a bear case for two years. If Snowflake makes its own engine more efficient, existing queries cost less, which theoretically compresses revenue.
That fear was legitimate and I’ll address it directly in the investment section.
The important context to carry forward is what kinds of workloads were about to start landing on the platform.
The Data Cloud and the Marketplace network effect
The architectural separation of compute from storage enabled something beyond query efficiency: data sharing without data movement.
If two companies both use Snowflake, Company A can give Company B a live, secure pointer to a dataset in A’s storage. B queries it directly against live data without A ever copying a file. When A updates the data, B sees the update automatically. No stale copy. No transfer pipeline. No data duplication that creates governance headaches.
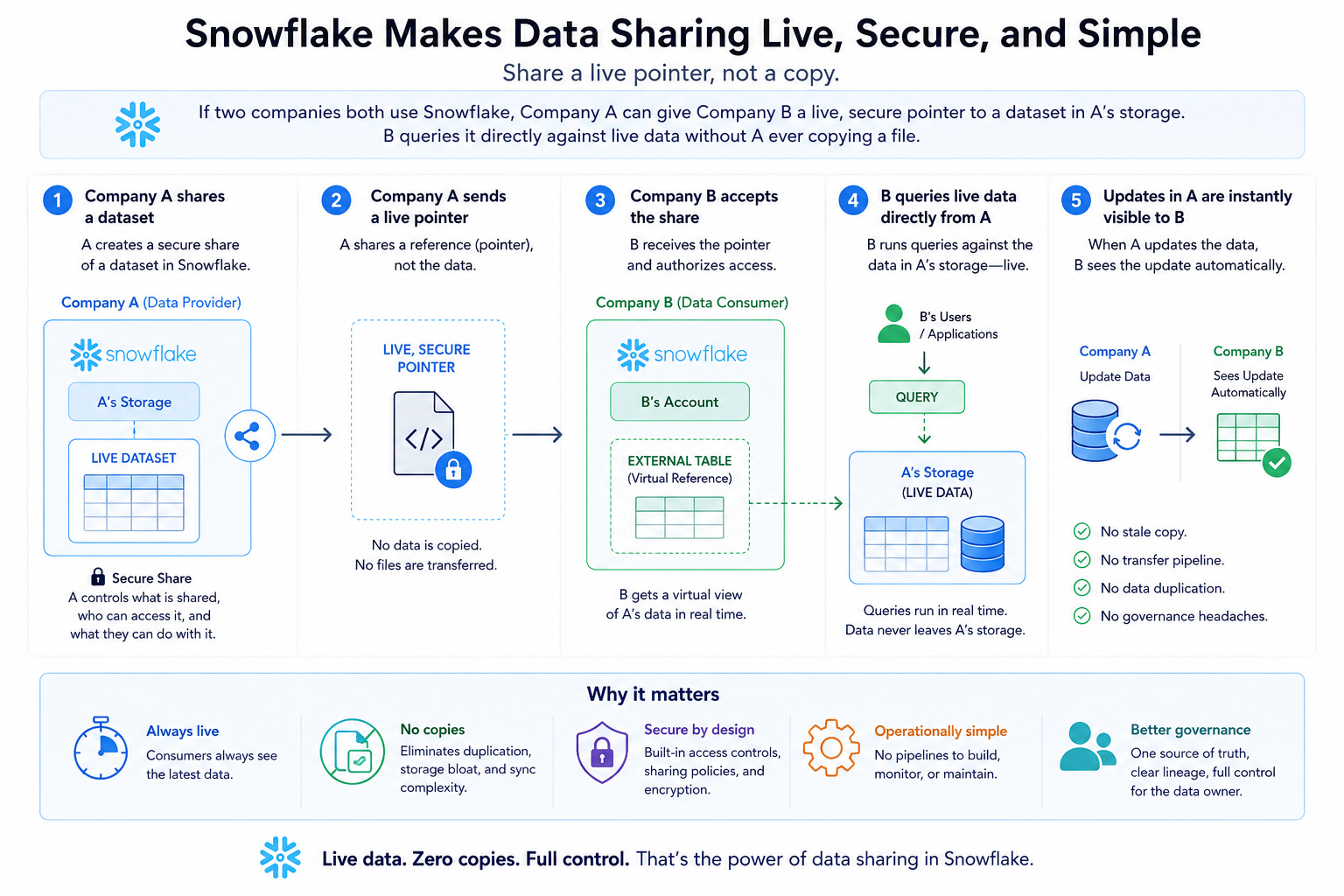
Snowflake formalized this mechanism into the Snowflake Marketplace.
By 2026 it holds over 3,000 listings from more than 700 providers: weather data, financial reference databases, healthcare claims, geospatial feeds, consumer behavior indices. An airline can subscribe to a weather data listing and join it live against its own flight operations data. A bank can access macroeconomic reference data and merge it with its internal loan book in a single query. No ETL pipeline to build. No copy to maintain.
This is the App Store for enterprise data, and it generates a network effect with a specific structure.
The more data providers list their products on Snowflake, the more valuable it is to be a Snowflake customer, which attracts more customers, which attracts more providers.
The network gets stickier as it grows, and each connection becomes infrastructure that companies build workflows on top of. Switching costs that emerge from a data marketplace are different from switching costs that emerge from a database lock-in. They are operational rather than technical, and they compound quietly over years.
The AI product stack
The company Sridhar Ramaswamy took over in early 2024 has built an AI layer directly on top of this foundation. Understanding it matters because this is where the Q1 acceleration came from, and where the next two years diverge from the previous two.
Cortex is the AI inference layer inside the platform. You can run large language models, including third-party ones like Anthropic’s Claude (a partnership deepened publicly at Summit 2026), against your own data inside the security perimeter of your Snowflake account. The model runs against the data. The data stays put, inside the compliance boundary. For a regulated enterprise in healthcare, finance, or legal services, this is the only viable architecture for production AI workloads.
Arctic is Snowflake’s own LLM, built with a mixture-of-experts architecture and released with open weights. It competes in a narrow lane: SQL generation and data tasks specifically, which happens to be exactly the leverage point the enterprise data world needs most.
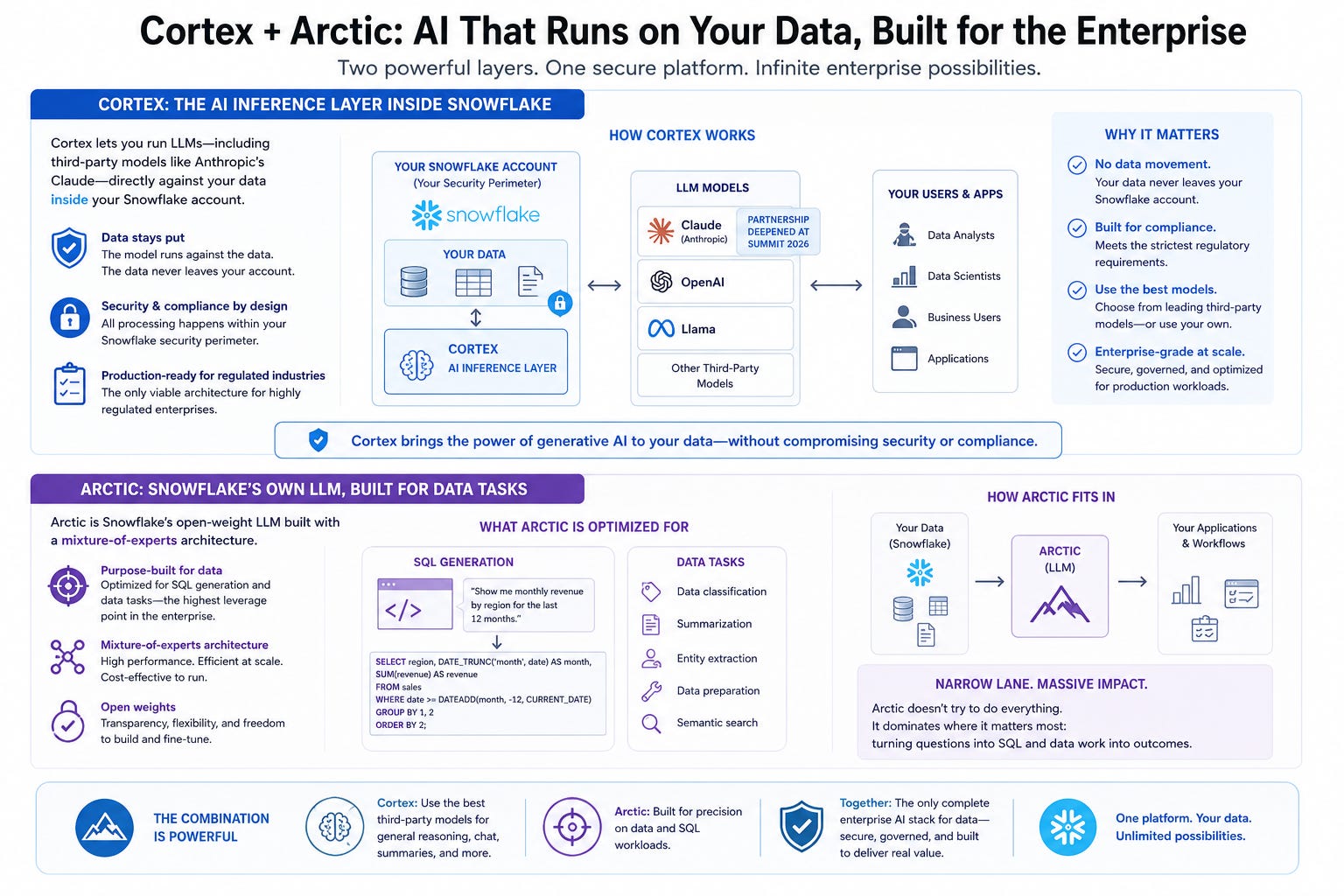
General reasoning is someone else’s game.
CoCo, rebranded from Cortex Code at Summit 2026, is a data-native AI coding agent. It reads your actual Snowflake schemas, access-control policies, and data lineage graphs before generating anything. The output is production-ready SQL and pipelines built for your specific environment, not a template that needs two days of cleanup before it can run. At the Summit, CoCo expanded to a desktop application, Slack integration, VS Code, and a mobile app in development. Fanatics described the practical result publicly: pipeline problems that used to consume days now resolve in hours.
CoWork, formerly Snowflake Intelligence, is the knowledge worker agent. A business user asks a question in plain language. CoWork accesses the governed data, runs multi-step reasoning across multiple sources, and returns an answer with supporting evidence, without requiring a data engineer to translate the request into SQL. Zero to 2,500 active accounts in the first three months of availability makes it the fastest-adopted product in the company’s history.
Natoma, acquired ahead of Summit 2026, is the MCP layer. The Model Context Protocol is emerging as the standard for AI agents to reach into external business systems and trigger actions. Snowflake acquired the company that built the enterprise-grade implementation of that protocol, with governance and a complete audit trail baked in.
The practical meaning: agents running in CoWork or CoCo can now act on data in downstream systems, with every action logged and attributable. The transition from AI that reads to AI that acts, under governance, is what Natoma enables.
The product stack is coherent in a way that matters for the investment thesis.
Every piece extends one thesis: your proprietary data, governed and structured, powering agents that act on it safely at scale. Summit 2026 added one more layer to that thesis with AI Agent Identity, which gives every AI agent a cryptographic identity with per-agent access controls and a complete audit trail. This is governance infrastructure for the agentic economy, built by a company that sees the control plane as its core product.
Emerald explains what that control plane means for the structural forces underneath the stock…
Why It’s Strategically Important
— Emerald, The 2nd Order
Start with the force.
AI has a data problem, and the timeline on it is compressed.
Epoch AI, the research group that tracks the stock of usable training data, dates the exhaustion of high-quality public text to roughly 2028.
The frontier models will have read everything worth reading on the open internet. After that, the marginal improvement in model capability comes from data that someone owns and nobody else can access.
Proprietary corpora, operational telemetry, regulated records, the exhaust of running a real business at scale.
This creates a structural shift in where value accumulates in the AI stack.
For three years the binding input on artificial intelligence was compute. A thesis we have been developing here:

Capital flowed to whoever could secure the most of it fastest, and the market priced that correctly. Nvidia went from a gaming chip company to one of the most valuable businesses on earth, Micron, SK Hynix too. The hyperscalers committed hundreds of billions to data center construction. That phase is maturing… Compute is becoming abundant, expensive but abundant, and abundance erodes pricing power, even if we see progress of the compute another growth engine for these companies due to Jevon’s paradox.

Watch where the capital has started voting instead.
Meta paid $14.3 billion in 2025 for roughly half of Scale AI, a data-labeling company, valuing it at $29 billion. The deal bought control over the supply of human-generated training data the labels were incidental and he backlash, instructive.
Google and OpenAI, unwilling to depend on a supplier half-owned by Meta, redirected their spending, and in doing so created two new winners nearly overnight: Surge AI, bootstrapped, now running above $1 billion in revenue, and Mercor, valued around $10 billion.
Nvidia acquired Gretel for synthetic data generation. RELX, News Corp, and S&P Global began licensing their archives directly to the labs. Each of these transactions is the same trade expressed differently.
Data is being repriced as the scarce asset of the next phase.
Now the second-order point, where most analysis stops.
Be precise about what the scarce asset actually is. The frontier of the problem has moved past training data. The next constraint is inference data: the proprietary, governed, operational data that sits inside enterprises and powers production AI applications. Becasue this data is almost always inaccessible in practice, it lives in incompatible silos. Half of it is ungoverned.
Most of it was generated by business processes never designed with machine-readability in mind.
Owning this data is worth little until it can be unified, governed, and made safe for an autonomous system to act on. The value pools one level up, at the control plane of that data: the layer that unifies it, governs access in real time, enforces compliance, and lets AI agents act on it with a verifiable audit trail. Holding the data is the easy part. Governing its flow at AI speed is where the toll sits.
Snowflake’s Summit 2026, attended by 20,000 people, announced AI Agent Identity: cryptographic identity for every AI agent, per-agent access controls, and a complete audit trail. This is governance infrastructure for the agentic economy, built by a company that has decided the control plane is its product. It is the kind of feature you announce when your enterprise customers are deploying agents in regulated industries and asking serious compliance questions.
The competitive dynamics reinforce the structural position.
The infrastructure underneath this layer is consolidating and commoditizing at speed. IBM acquired Confluent for roughly $11 billion in December 2025, absorbing the streaming layer. Fivetran and dbt merged, consolidating the ingestion and transformation layer. The hyperscalers bundle their own data tooling into cloud contracts and discount it aggressively to win workloads. This is sustained pressure on the commodity layer.
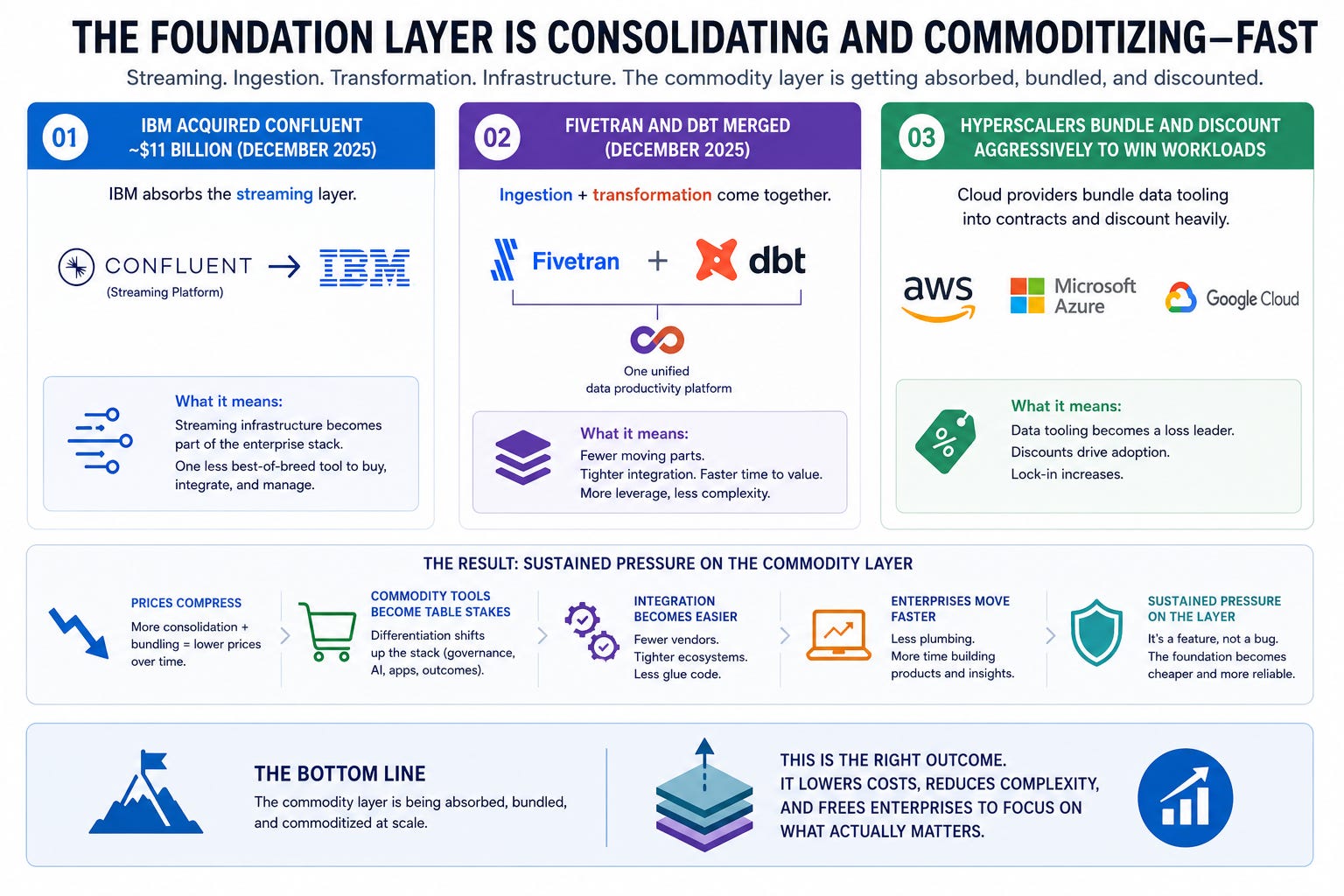
Snowflake’s position sits above that commodity layer. The multi-cloud architecture is structurally impossible for any single hyperscaler to replicate, because no hyperscaler is neutral between AWS, Google Cloud, and Azure.
The marketplace of 3,000 live data connections creates switching costs that emerge from operational dependency, not technical lock-in, and they compound quietly over years. The governance layer, developed for regulated industries at scale, is a moat that open-source alternatives have not yet matched in production enterprise deployments.
Databricks, at a private valuation of around $134 billion, is the most serious alternative. Its engineering quality is real, its open-source DNA is an advantage in certain workloads, and it will eventually go public, forcing a direct comparison. But it has not replicated the Marketplace network effect at scale, which is the one structural advantage that compounds most durably in this layer.
A structural tailwind names the layer. It stops short of naming the winner inside that layer. The investment case does the rest.
The Investment Case
— Hidden Market Gems : Emerald
I spent the first four months of 2026 watching Snowflake get treated like a slow-motion obituary. Every quarter it beat expectations. Every quarter the stock fell anyway, which is the kind of thing that starts to feel almost personal if you have been paying attention to the underlying numbers… For real…
By the tenth of April it had given back 56% from its highs and was sitting at $140, and the debate around it had shifted from valuation arguments to something closer to a structural verdict. People were asking whether the consumption model itself was quietly broken.
The bear case had four legs, and all four were reasonable on their face. That is what made the dislocation real.
The first was the consumption efficiency argument: Snowflake had spent two years making its own platform cheaper to run, with better compression and open formats like Iceberg.
Customers were doing the same workloads for less money, so, slower bills, slower revenue. A company optimizing itself into a declining top line.
The second was Databricks: a private competitor valued north of $100 billion, embedded in the data science and ML ecosystem through years of open-source investment, gaining enterprise ground fast.
The third was the profitability timeline: GAAP losses persisting, stock-based compensation eating around a third of revenue! And the quarter where that resolved stayed stubbornly out of view on any reasonable projection.
The fourth was a class action filed in the spring…Alleging misrepresentation of consumption growth. Lawsuits of this kind rarely shift the fundamental business but they are very effective at scaring marginal holders out of a name already in a downtrend.
Put all four together and you have a stock that everyone willing to be frightened out of, was. In my experience, that tends to mark the zone of maximum dislocation rather than the moment to exit.
Why the bears read the flywheel backwards
The consumption model is the flywheel.
The bears had been reading it as a slow leak… (if they’d have read Future Cognitive Capital, they would not have made the mistake…)
The mechanism they missed: when a customer runs more workloads on the platform, Snowflake earns more revenue. The workloads arriving in enterprise computing right now are AI agents, CoWork sessions, CoCo builds, Cortex inference calls.
Processes that run continuously, around the clock, at volumes far beyond what human-driven queries produce in a week. A BI dashboard that a human refreshes on Tuesday afternoon is a trickle. An agent running overnight, pulling data every few minutes, querying across multiple sources to assemble a report by 6am, is a steady current.
The efficiency gains that frightened the bears are the thing that pulls those workloads onto the platform in the first place. A cheaper per-query cost means more queries get run. Software running around the clock on a cheap per-query rate drives more total consumption than an expensive human analyst who runs ten queries a week. The bears built a model where falling unit prices shrink the business.
The actual mechanism is that falling unit prices expand the surface area of what gets run.
The evidence was accumulating in the one metric that matters most for a consumption business: net revenue retention, which measures how much existing customers spend this year versus last.
It had sat flat at 125% for three consecutive quarters, indicating healthy expansion but no acceleration. That plateau was what scared the momentum money out and the flywheel was already spinning at a healthy rate.
The tape stopped looking at it?
So, what the print proved
May 27 resolved the debate.
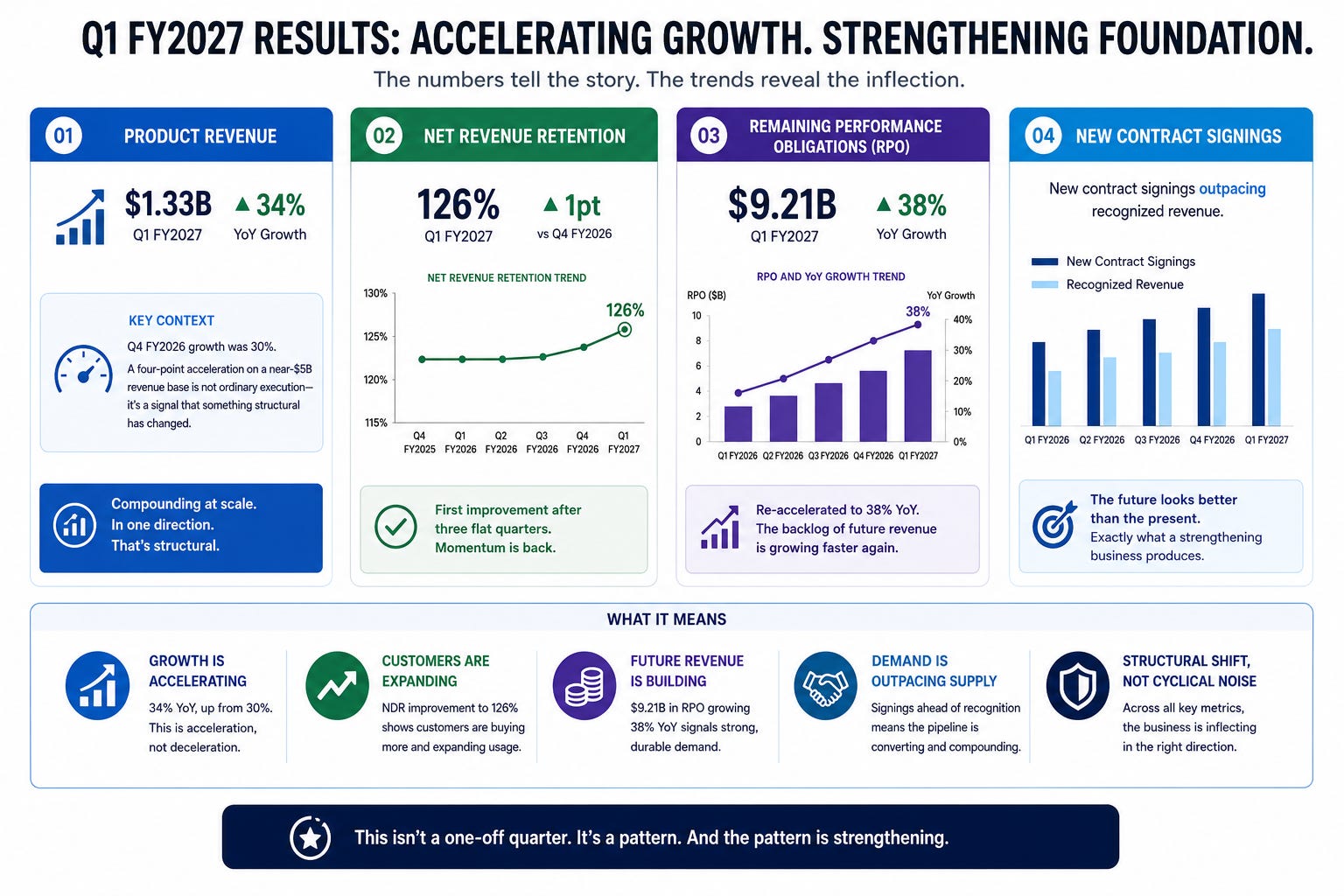
Product revenue landed at $1.33 billion for Q1 FY2027, up 34% year over year.
That number gains full meaning only in context: the quarter before, growth was 30%. A four-point acceleration on a near-$5 billion revenue base is the kind of data point ordinary execution rarely produces.
Compounding at that scale, in one direction, means something structural has flipped in the underlying demand pattern.
Net revenue retention ticked up to 126%, its first improvement after three flat quarters.
Remaining performance obligations reached $9.21 billion and re-accelerated to 38% year-over-year growth.
New contract signings outpacing recognized revenue means the future looked better than the present, which is precisely what a strengthening business produces.
Two operational details told the deeper story
Snowflake added 17 net employees organically during the quarter, excluding the Observe acquisition. Seventeen. A company growing 34% on 17 net hires is running its operations on its own AI tools in production, and the financial result was immediate: a record non-GAAP operating margin of 11.9%, and a net loss that narrowed to $295.6 million. This is what operating leverage from internal AI adoption looks like in a quarterly print.
Then the guidance rose
Snowflake lifted full-year product revenue guidance to $5.84 billion, shifting the implied growth rate from 27% to 31%, and raised its operating margin target from 12.5% to 13.5% simultaneously.
Raising both at once, mid-year, ranks among the largest upward revisions in company history. At the Investor Day on June 2 they set a GAAP profitability target for the first time: Q4 of fiscal 2028.
Then the strategic confirmation Emerald had been describing:
A $6 billion multi-year infrastructure agreement with AWS. The Natoma acquisition, turning the data layer into an agent control plane. Deepened partnerships with Anthropic and SAP. And at the Summit the following week, 26 new product capabilities announced across six domains, attended by 20,000 people, with CoWork and CoCo described by the CEO as the fastest-adopted products in company history.
The stock moved 37% on earnings night and pushed higher through the Summit before settling back to around $238 by June 5. The re-rating had started.
The valuation question
At $238, Snowflake is expensive by any conventional screen.
The stock trades around 13 to 14 times next-twelve-month EV/revenue, with a market capitalization of roughly $83 billion. Morningstar’s fair value estimate sits at $214, implying a 10% premium to their model.
One bullish institutional model carries a price target above $600. More than thirty analysts raised their targets in a single day after the print. Barclays moved to $285 on June 4.
That spread reflects two genuinely different frameworks.
The bears apply a software multiple to a business with real near-term risks, consumption volatility, competition, GAAP losses.
The bulls apply a platform multiple to a business with a network-effect moat, durable growth above 30%, a credible path to real profitability, and agentic optionality the forward guidance treats as future upside rather than current revenue. Both are internally consistent. The contest between them gets settled by the next two quarterly prints.
The first leg and the second leg
My answer to whether the re-rating is done: the first leg is done.
The second leg is the actual trade.
The first leg was the de-rating reversal, $140 back to $238, as the market accepted that the consumption flywheel was accelerating.
Buying today for a repeat of that specific move means buying yesterday’s catalyst.
The second leg lives inside the guidance itself.
The raised FY2027 forecast was built entirely on observed consumption, the workloads management can already see running on the platform.
It was built on the observed base, treating the newest products as future optionality rather than current revenue.
CoWork went from zero to 2,500 accounts in three months.
CoCo is compressing migration projects from 18 months to weeks. Neither product’s adoption curve appears in the annual guidance.
If they convert into consumption over the next few prints, the company beats a guide that already looked strong, and the multiple gets defended by revenue the market never priced in.
That is the asymmetry that remains for investors entering today.
What kills it
The honest accounting, plainly.
Consumption can decelerate.
The same model that generated the Q1 acceleration can reverse in a soft enterprise spending quarter, and a 14-times-revenue multiple gives back its gains fast when that happens.
Databricks remains a serious competitor with deep pockets and an IPO that will eventually force a direct public comparison.
Hyperscaler bundling continues to pressure the data tools around Snowflake’s edges.
The class action is outstanding. Stock-based compensation, though declining, still weighs on GAAP results and limits the institutional universe that can own the name without an earnings hurdle.
And the clearest signal of all, the one the entire thesis hinges on: whether the second in-year guidance raise arrives at the next print. A company that raises twice mid-year confirms a structural inflection. A company that raises once and then holds is telling you the first raise was real and the current level is the new equilibrium.
That single datapoint is worth more than any valuation model for us.
What we’re watching now
Both desks want to return to this name, because the setup resolves itself over a short window. The next two quarterly prints settle the core debate.
The leading indicators for the bull case are net revenue retention holding at or above 126%, and the account growth of CoWork and CoCo specifically, because their adoption represents the incremental consumption the guidance never counted.
Those two numbers together are the actual second-leg signal.
On the strategic front, the key questions are whether the $6 billion AWS agreement accelerates workload migration in the reported numbers, whether Natoma’s MCP integration emerges as a new billable surface, and whether the Anthropic partnership drives measurable Cortex usage at scale.
On the people side, the first full fiscal quarter under the new Chief Revenue Officer will tell whether the commercial motion has changed, and the co-founder’s board transition will reveal over the next several months whether it was a clean succession or the beginning of drift.
The balance sheet progression tells a secondary story: stock-based compensation declining from a third of revenue toward a quarter is the visible proof of the profitability path, and the FY2028 GAAP target needs to survive contact with reality quarter by quarter.
The one external variable that resets the competitive framing entirely is a Databricks IPO or major fundraising event, which forces a direct public comparison and resets how the market thinks about relative valuation in the data platform layer.
— Hidden Market Gems & Emerald from The 2nd Order.
 | A guest post by
|
 | A guest post by
|